
Title
오늘은 KL-divergence 에 대해서 알아보겠다. 하지만 이 개념을 설명하기 앞서서, 미리 알아야할 내용들이 있기때문에 그 내용들을 먼저 설명하고 진행을 하겠다.
Cross Entorpy
크로스 엔트로피를 한마디로 정의하자면, ‘예측과 달라서 생기는 정보량’ 이라 할 수 있다. 딥러닝을 조금이라도 공부한 사람이라면 모를리 없을테지만 초심자를 위히여 보다 자세히 설명하겠다.
먼저 Binary Case에 대해서 알아보자.
Binary case 의 Cross Entorpy
알다싶이 binary case 의 경우 0, 1 두개의 상황만이 존재한다.
- $y$를 target $\hat{y}$ 예측값이라 한다.
- 이때 다음과 같은 식이 성립한다.
$$ BCE = -ylog(\hat{y}) - (1 - y)log(1 - \hat{y}) $$
따라서 target의 값과 예측값 $\hat{y}$값이 같다면 0 아니라면 무한대가 나옴을 알 수 있다.
여러가지 case에 대한 Cross Entropy
Binary의 경우 Cross Entropy의 값이 타겟값과 모델의 출력값이 다른 정도를 나타냄을 알 수 있다.
따라서, 다음의 경우처럼 식을 제시할 수 ‘도’ 있다.
$$ BCE = \sum_{x\in0,1} (-P(X)log(Q(X))) $$
- $P(X)$는 희망하는 타겟값을 의미한다.
- $Q(X)$는 모델이 출력한 값(예측값)을 의미한다.
이를 조금 더 일반화하여, 다음과 같이 식을 제시할 수 있다.
$$ CE = \sum_{x\in X} (-P(x)log(Q(x))) $$
그렇다면 위의 식으로 유도되는 의미는 무엇일까?
그것은 CE는 Q 라는 모델의 결과에 대해 P 라는 이상적인 값을 기대했을 때 우리가 얻게되는 ‘어지러움(?)’에 대한 값을 정보량으로 표현한 것이라는 점이다.
내가 참고한 블로그는 어지러움을 ‘놀라움’ 으로 표현하였다. 난 개인적으로는 ‘엔트로피’라는 말에 걸맞게 어지러움 이라고 표현을 하였다.
위의 식을 가지고 예제에 적용시켜보자!
- 정상적인 주사위가 있다. 몰론 확률은 1/6
- 비정상적 주사위 또한 존재한다. 확률은 그냥 랜덤. (합은 1)
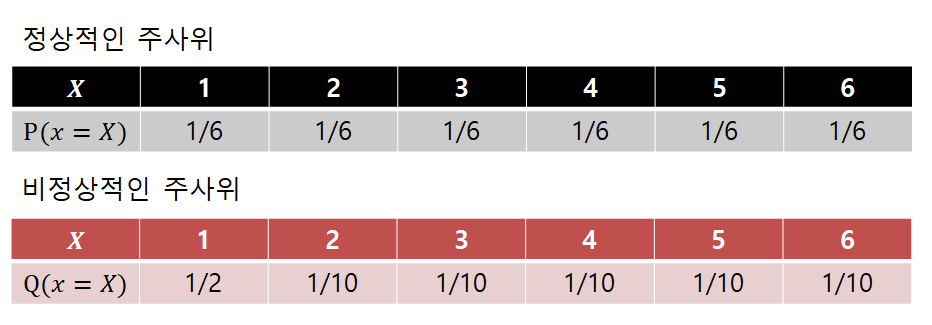
따라서 위의 두 주사위의 CE 를 계산하면, 비정상적 주사위의 CE 결과값이 더 높다.
즉 비정상적인 주사위가 더 ‘어지러움’ 의 정도가 크다는 것이다. (랜덤성이 크다 라고 해석해도 될것같다.)
KL dirvergence
드디어 대망의 KL divergence이다. 먼저 내가 공부한 바에 의한 정의를 설명하자면
‘P 분포와 Q 분포가 얼마나 다른지를 측정하는 방법. 여기서 통계적으로 P는 사후, Q는 사전분포를 의미한다.’
사후분포(사건이 일어난 후의 분포)란 당연히 결과값 (target)을 의미하고 Q사전분포는(사건이 일어나기 전의 분포) 당연히 예측값을 의미한다.
텐서플로우 공식 문서에 정의되어있는 용어로 설명해보면, KLD는 y_true(P)가 가지는 분포값과 y_pred(Q)가 가지는 분포값이 얼마나 다른지를 확인하는 방법이다.
즉! KLD는 값이 낮을수록 두 분포가 유사하다라고 해석한다.
따라서 수식으로 보도록 하자.
$$ D_{KL} (P\parallel Q) = \sum_{x\in X}P(x)log_b (\frac{P(x)}{Q(x)}) $$
위 식을 전개한다면,
$$ -\sum_{x\in X} P(x)log_b (\frac{P(x)}{Q(x)}) $$
$$ => -\sum_{x\in X} P(x)lob_b Q(x) + \sum_{x\in X} P(x)log_b(P(x)) $$
위의 식은 각각 기댓값으로 표현할 수 있으므로,
$$ => -E_P [log_b (Q(x))] + E_P [log_b P(x)] $$
$$ => H_P (Q) - H(P) $$
즉 P의 기준으로 봤을 때의 Q에 대한 크로스 엔트로피를 의미하고 H(P)는 P에 대한 정보 엔트로피를 의미한다.
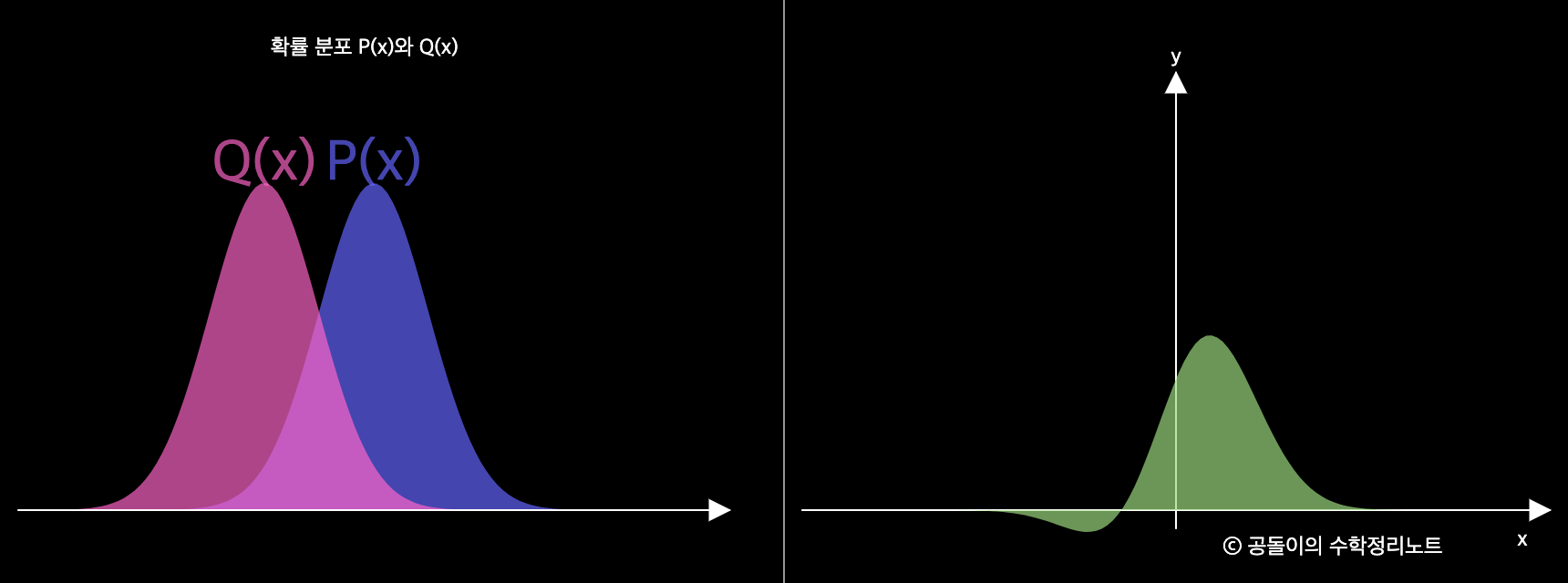
위의 사진을 볼때, 초록색의 넓이가 KL-divergence 의 값을 의미한다. 즉 두 확률분포가 유사하다면, 그 값이 작을것이고 유사하지않다면 그 값이 클것이다.
때문에, KL-divergence가 분포값이 얼마나 다른지를 측정하는 식이라고 할 수 있다.
Reference
https://angeloyeo.github.io/2020/10/27/KL_divergence.html - 공돌이의 수학정리노트